MIT 6.5840 分布式系统(Spring 2023)丨Lab 2:Raft的极致优化,Part 2D测试时间缩短到115s!
这篇文章记录了我在Lab 2中对Raft的实现的优化。优化后,大部分测试数据都要大幅优于课程中提供的典型测试数据以及其他博客公开的实现。在时间上,Part 2B、Part 2D分别比实现1快36%、38%,比实现2快43%、52%。吞吐量也远比课程中提供的典型测试数据要高。基于优化后的Raft实现的KV存储系统,在本地测试模拟10个客户端、5个服务端下最高超过8800QPS。
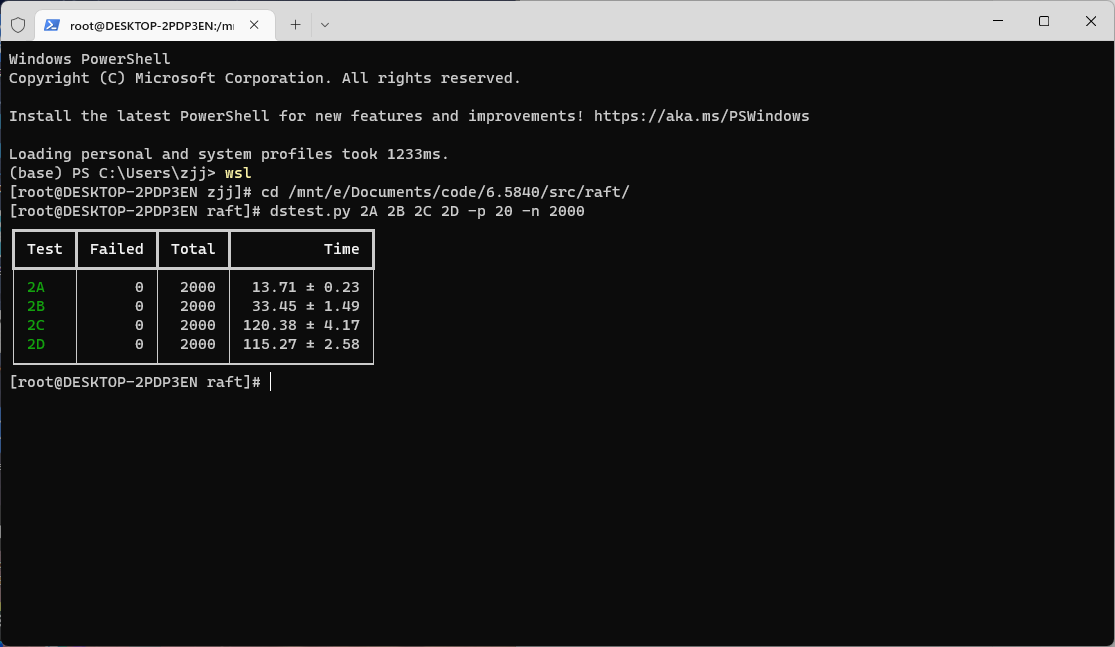
MIT 6.5840课程的测试用例记录了程序运行的时间、RPC次数、RPC的数据总量以及提交日志的数量等测试数据,在实验中,可以通过观察这些数值来判断实现的Raft的性能。除此之外,在Linux中,也可以通过使用time工具可以查看代码运行的真实时间、CPU时间和系统时间来判断程序资源占用的情况。在这篇文章中,我将从时间、资源和锁三个方面描述我在实现Raft的过程中的优化过程。
以下为优化后Lab 2测试通过2000次的结果:
时间的优化
Raft是一种强一致性的分布式共识算法,如果业务要求任意一次读操作都能返回上次写的结果,那么无论是读请求还是写请求都必须要通过Leader完成,而不能通过Follower。因此对于一个要求强一致的业务来说,响应延迟便显得非常重要,并且它是最影响用户体验的一个指标。在正常情况下,Raft的响应延迟主要在于Leader与各个Follower的同步过程,只要将日志复制到一半以上的节点,Leader就可以向上层服务中应用操作并返回给客户端;在网络异常情况下,响应延迟主要来源于Raft节点之间的通信,如果有客户端,响应延迟还来源于客户端与服务端之间(Lab 3中实现)。在实现过程中,我主要从这两方面对Raft的响应时间进行优化。
网络正常情况下的优化
优化一:快速log catch up
在6.5840的Lecture 6中,Frans Kaashoek介绍了一种快速log catch up的方式,即当服务器失败重启时,快速将日志恢复为最新状态的方法,Part 2C的课程任务中也描述了课程中讲授的方法:
You will probably need the optimization that backs up nextIndex by more than one entry at a time. Look at the extended Raft paper starting at the bottom of page 7 and top of page 8 (marked by a gray line). The paper is vague about the details; you will need to fill in the gaps. One possibility is to have a rejection message include:
XTerm: term in the conflicting entry (if any)
XIndex: index of first entry with that term (if any)
XLen: log lengthThen the leader’s logic can be something like:
Case 1: leader doesn’t have XTerm:
nextIndex = XIndex
Case 2: leader has XTerm:
nextIndex = leader’s last entry for XTerm
Case 3: follower’s log is too short:
nextIndex = XLen
它的主要思路如下:
- 如果Follower在RPC参数中的
prevLogIndex处的日志为空,则将Follower的日志长度返回给Leader,Leader将从该长度处开始同步。 - 如果Follower在RPC参数中的
prevLogIndex处的日志的term与prevLogTerm产生冲突,则将冲突处的term值和该term的第一条日志的index返回给Leader节点;若Leader节点包含该term的日志,则从该term在Leader日志中的最后一条日志处开始同步,否则从返回的index处开始同步。
与论文中一条一条日志进行同步相比,这种方法相当于一个一个term进行同步,可以节省大量的RPC数量,从而节省时间。从直觉上来讲,一个Follower如果与Leader有冲突的日志,那么这个Follower要么是一个旧的Leader,在宕机前接收了日志但是还没来得及与其他Follower同步,要么是一个和旧的Leader在同一个网络分区的Follower。在网络恢复后或者宕机重启后,新Leader的term必然比之前大,之前的term接收的但未同步的日志是要被覆写的,因此一个一个term进行同步是合理的。
根据课程提供的思路方案,这个优化实现起来并不难,只需在请求与响应参数中添加一些字段,并在判断日志冲突后进行操作即可,这里就不放代码实现了。
但是只实现这个优化是远远不够的。在通过Part 2B的基础上,如果只加了这个优化,是无法通过Part 2C的。
优化二:请求返回快速同步
在Leader调用AppendEntries RPC返回响应后,如果日志还是旧的,并且等到下一个心跳才继续发送下一个AppendEntries RPC的话,这样也太慢了。如果处理完响应后立马再次向该Follower发送一个RPC,可以大大提高响应速度。
我们可以在Leader中给每个Follower设置一个条件变量,在向Follower发送完请求后调用Wait()进入等待,当处理完请求后,若判断到日志在请求与响应过程中有更新,即Follower日志不是最新,则立刻调用Broadcast()通知再次发送。实现过程中,我希望可以在Wait()中传入时间参数从而时间超时等待,这样就能与Raft的heartbeat机制完美配合。遗憾的是,Go中的Wait()不能传入时间参数,只能自己动手实现。参考Stack Overflow,我实现了类似的waitTimeout()函数:
1 | func waitTimeout(cond *sync.Cond, timeout time.Duration) bool { |
上面这个函数有一个可能导致goroutine leak的bug,留给你来思考。
当然,你也可以直接通过Go的channel和select来实现,但是要注意考虑到channel的阻塞问题,要小心使用。
AppendEntries RPC请求返回后处理的代码如下:
1 | // call AppendEntries RPC |
同样的,对于InstallSnapshot RPC,也可以加上这个优化:
1 | if peer.Call("Raft.InstallSnapshot", args, reply) { |
优化三:调用Start()快速同步
如果Leader在等待下一个心跳的过程中接收到了新的日志,应该立即向所有的Follower发送AppendEntries RPC进行同步。我们只需要在上层服务调用Start()时通知所有给Follower节点发送AppendEntries RPC的goroutine即可:
1 | func (rf *Raft) Start(command interface{}) (int, int, bool) { |
优化四:commitIndex更新快速同步
对于一个Raft节点来说,如果一条日志已经提交,那么它会立即向上层服务报告,如果是Leader,还会向客户端返回成功的结果。由于Raft是强一致性的算法,无论是读请求还是写请求都必须要经过Leader,因此只要Leader已经提交日志,那么日志便不会丢失(因为日志已经在一半以上的节点复制了)。这样看来,如果一条日志在Leader节点上已经提交,而在Follower节点上并未提交,这种情况其实对于要求强一致性的业务来说没有任何的影响。
但是如果有业务场景并不要求强一致性,只追求最终一致性,那么其实正常情况下在Follower上进行读操作问题也不大,这样就能将读操作的压力分散到各个Follower节点中,这时如果分布式系统的各个节点能够越快保持一致,对业务的影响越小。Lab 2的测试配置中的one()函数就是要求有expectedServers数量的Raft节点提交才算测试通过:
1 | func (cfg *config) one(cmd interface{}, expectedServers int, retry bool) int { |
上述代码在/src/raft/config.go的第582~595行。它每20毫秒检查一次有多少个Raft节点提交了日志,如果2秒内没有expectedServers数量的节点提交了日志,并且不需要重试的话,那么便会导致测试失败。因此对于测试用例来说,各个节点同步越快,测试时间花费的越少。
在我的实现中,每当一个AppendEntries RPC响应处理完后,Leader会检查commitIndex是否需要更新。我们只需要在更新commitIndex的函数中加上唤醒的逻辑即可:
1 | if peer.Call("Raft.AppendEntries", args, reply) { |
需要注意的是,如果commitIndex更新了,那么将唤醒所有向Follower节点发送AppendEntries RPC的goroutine,因此不必再执行优化二判断该节点日志是否最新了。
网络异常情况下的优化
执行完优化一~优化四,你的Raft应该能通过20次的failure-free的Lab 2的测试了,但是如果要想稳定通过100次以上,还需要进行其他的优化,尤其是对于Part 2C中的TestFigure8Unreliable2C。这个测试模拟了不可靠的网络,在调用RPC时可能会出现请求丢失的情况,需要非常耐心地处理。
优化五:快速重试AppendEntries RPC
在初次进行Part 2C的测试过程中,你很可能看到这样的日志:
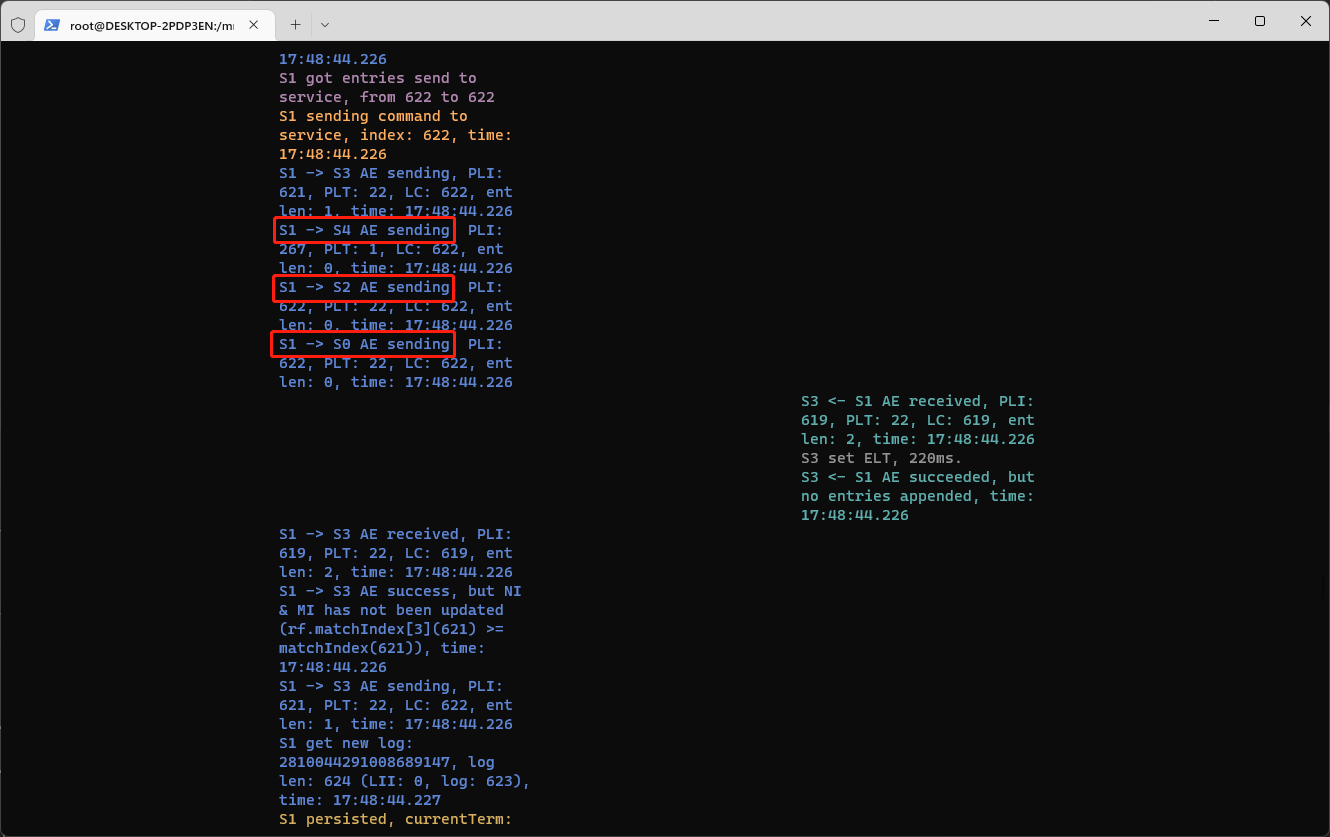
RPC请求明明发送过去了,但是Follower迟迟没有接收到,查看测试代码,此时并没有发生网络分区,实在是让人摸不着头脑。但是你如果仔细分析了测试代码中的unreliable参数,或者阅读了Lab提供的Advice,你就会明白:测试用例中的网络并不总是可靠的!
Keep in mind that the network can delay RPCs and RPC replies, and when you send concurrent RPCs, the network can re-order requests and replies.
请记住,网络可能会延迟RPC的请求和响应,当你并发调用RPC时,网络可能会重新安排请求和回复的顺序。
现实情况也是如此,即使TCP在一定程度上保证了数据传输的可靠性,但是在网络发生拥塞时仍然可能会有丢包的情况。为了加速各节点间的同步,我们需要考虑到这种情况。
我采用的方案是:重试。设定一个超时重试时间间隔unreliableAERetryInterval和一个超时重试次数unreliableAERetryCount,例如20ms。若首次发送后超时后没有收到响应,则进行重试。每隔unreliableAERetryInterval重试一次,直到收到响应或者达到超时重试次数unreliableAERetryCount。
为了处理节点宕机或者发生网络分区的情况,我还采用了另外一个策略:如果重试次数达到unreliableAERetryCount仍然没有收到节点的响应,那么就判断这个节点宕机。对于宕机的节点,Leader除了发送正常的心跳包以外,不再进行重试,直到收到节点的某个RPC响应。这种策略既可以在发生网络拥塞时快速重试,又可以很好地在发生网络分区或者宕机时减少RPC的调用次数,节省网络资源。
以下是我的实现的部分代码:
1 | func (rf *Raft) tickerHeartbeat(currentTerm int, idx int) { |
每个节点运行一个goroutine,当发生超时,retryCnt自增,若重试达到最大次数,将对应节点的peerIsDown设置为true。只有在接收到之前发送的某个RPC的响应时,才会将peerIsDown重新设置为true。
优化六:快速重试RequestVote RPC
为了保证日志的完整性,Raft对于选举的Leader有一定的限制,即需要保证节点的日志要足够“新”。因此并不是每一个节点都能被选举为Leader,在网络异常的情况下,这种限制加剧了选举时的不稳定性,很可能长时间无法选举出Leader,导致测试失败。更多细节可以参考《Lab 2:Raft的踩坑记录》。
实验验证
为了验证这些优化的有效性,我进行了大量的对比实验:
对每个优化单独进行验证
我分别验证并获得了以下实验条件下的测试结果:
- 没有任何优化
- 只应用单个优化
- 优化五和优化六一起应用
实验结果如下:

从实验结果中可以看出,在20次测试中没有任何一个优化可以完全通过Part 2C,表现最好的一个是优化一,即课程建议进行的优化。
对优化进行组合验证
在应用优化一的基础上,我逐个增加优化进行验证,即进行如下实验:
- 只应用优化一
- 应用优化一和优化二
- 应用优化一、优化二和优化三
- 应用优化一、优化二、优化三和优化四
- 应用优化一、优化二、优化三、优化四和优化五
- 应用优化一、优化二、优化三、优化四、优化五和优化六
实验结果如下:

为了更好地对比,我画了一个柱状图如下:
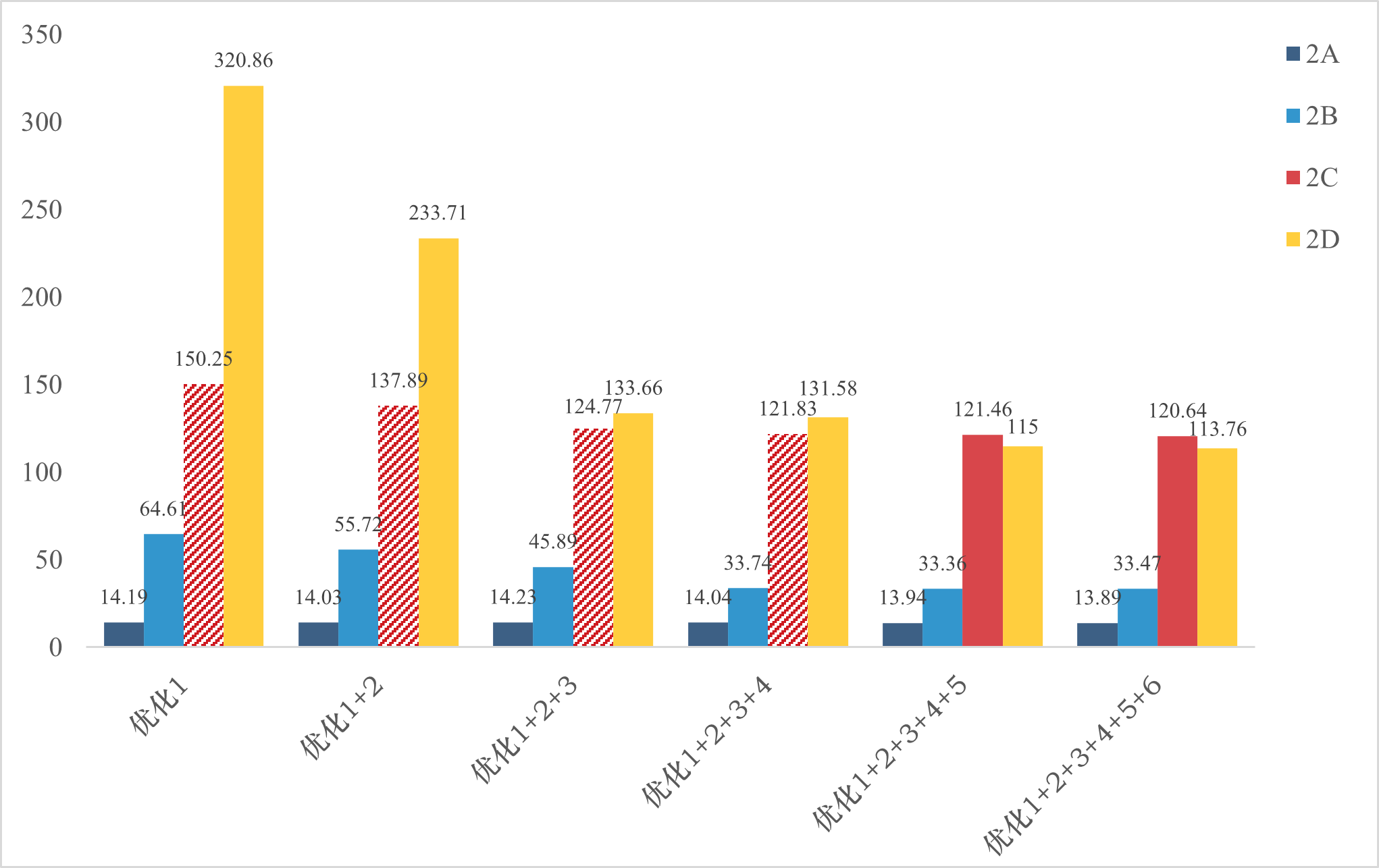
从图中可以看出,随着各个优化的应用,测试时间逐步减少。对于时间影响最明显的是Part 2D,随着优化的应用测试时间降低很明显。通过实验结果,验证了这些优化的有效性。
我的Raft实现的各部分测试的典型测试数据如下:
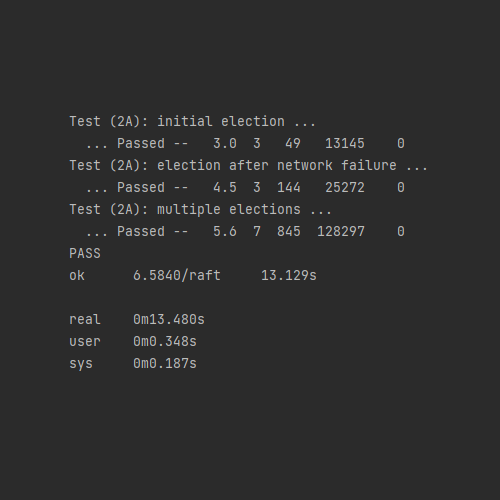
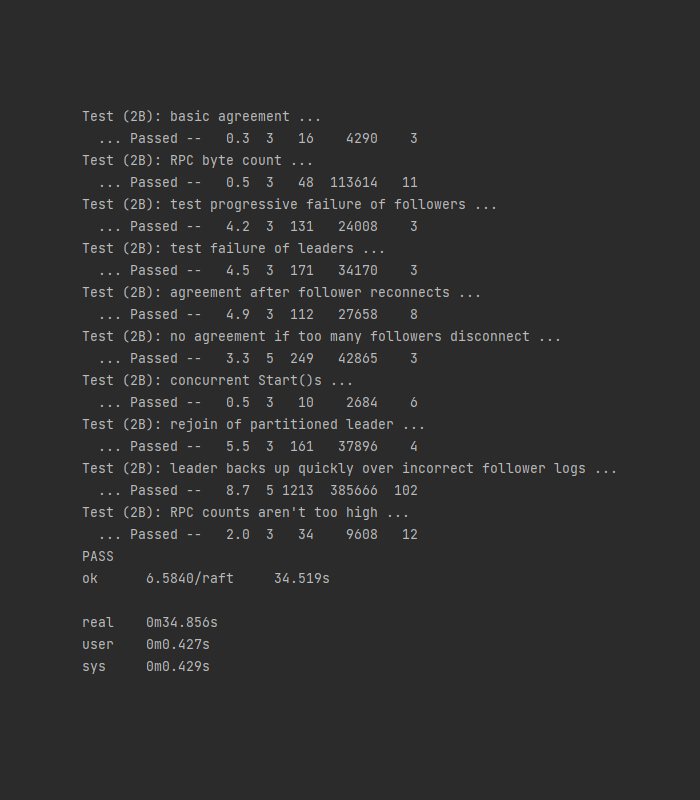
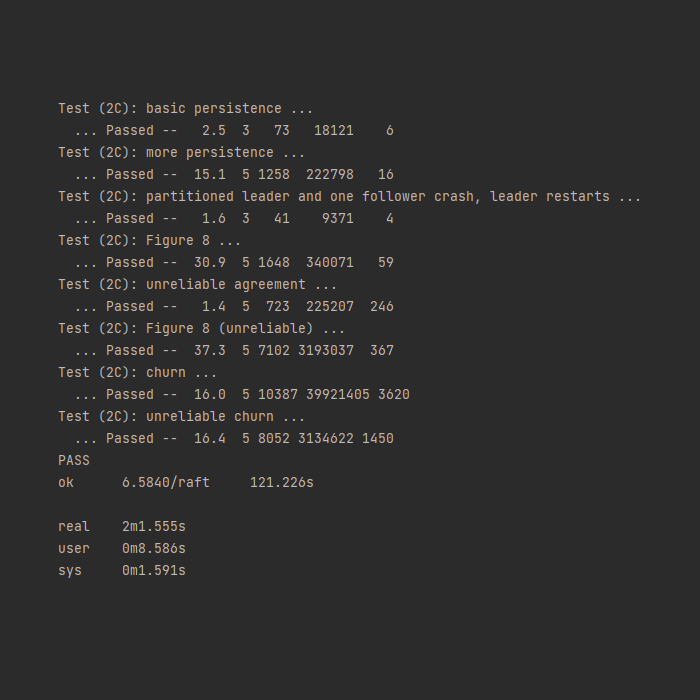
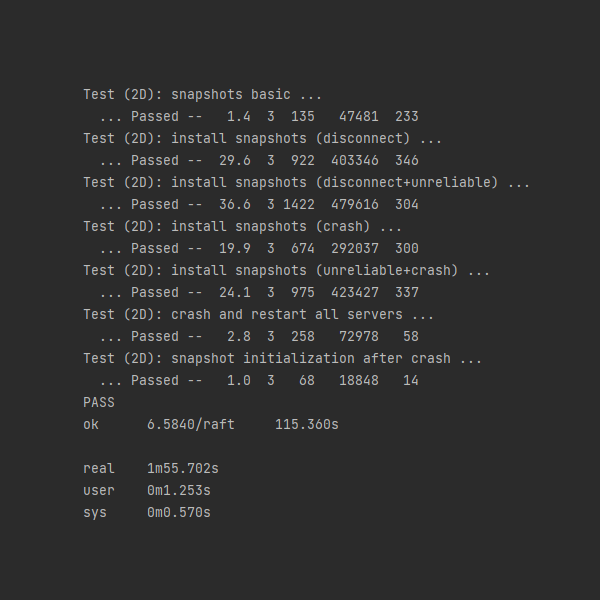
在应用各个优化之后,RPC数量、RPC数据量与提供的典型测试数据相比,相近或更优。由于使用了重试机制,在unreliable的测试条件下,部分测试RPC的数量和数据量会更高,同时提交的日志数量也更高。
资源的优化
异步批量发送
在实现优化三的过程中,我就一直在思考:如果每调用一次Start()就唤醒各个发送AppendEntries RPC的线程,那在请求高峰期,RPC岂不是会发送得非常频繁?这样的话多浪费网络资源和CPU资源!
于是在通过测试后,我开始思考如何去避免网络资源和CPU资源的浪费,提高同步的效率。
从MySQL的redo log的组提交策略和Kafka的异步批量发送的设计中受到启发,我在Raft中实现了类似的机制。
MySQL的组提交策略
MySQL中,在有数据页修改时,redo log与binlog的写盘的步骤总体是这样的:
- 先写redo log到log buffer中,并处于prepare阶段
- 再写binlog到对应的binlog cache中
- redo log调用fsync,然后binlog调用fsync,提交事务,处于commit状态
redo log把调用fsync刷盘的时机延后到了binlog刷盘之前,因此在步骤2的过程中,如果有其他事务往redo log写入数据,那么在步骤3中就可以一并提交。这种策略称为组提交机制,可以降低刷盘次数,节约IOPS。
Kafka的异步批量发送
Kafka的消息是以“批”为单位进行处理的。当客户端(生产者)向Broker发送一条消息时,实际上它不是将这条消息立刻发送的,而是先在内存中缓存,等到合适的时机再把缓存中的所有消息组成一批,再一并发给Broker。
在服务端进行处理时,它也是一批一批进行处理,直到消息到达消费者,它才会把批消息解开进行处理。
Kafka的这种批量处理机制减少了请求处理的次数,减轻了服务器的压力,提升了总体的处理能力。
从MySQL和Kafka得到启发
在Raft中,我考虑Leader节点在收到上层服务的同步请求时,延迟一段时间再向Follower节点发送AppendEntries RPC,而不是立刻发送,Leader接收到一定量的消息之后再发送请求,在高并发时可以显著减少RPC次数,降低服务器压力。
具体实现逻辑是,当节点成为Leader时创建一个goroutine,这个goroutine专门负责通知所有给各节点发送AppendEntries RPC的goroutine,让其发送AppendEntries RPC,代码如下:
1 | func (rf *Raft) broadcastInterval(currentTerm int) { |
当优化三中的rf.cond.Broadcast()调用时,它会被唤醒并从第4行代码开始执行,睡眠rf.syncInterval后向所有的节点发送RPC。
模拟验证
在完成Lab 3后,我使用Lab 3提供测试用例进行了测试,模拟了10个客户端、5个服务端节点,分别测试了立即发送和延迟1~5ms,测试结果如下:
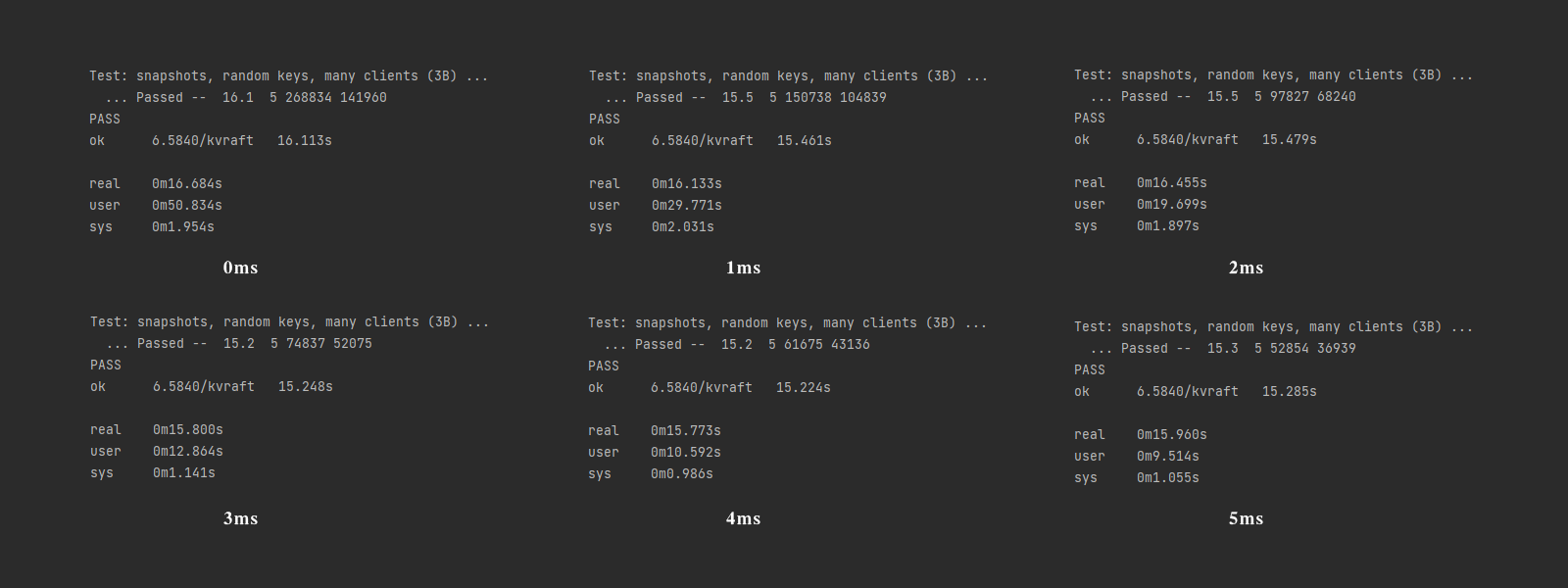
画出RPC数量和用户时间的柱状图如下:
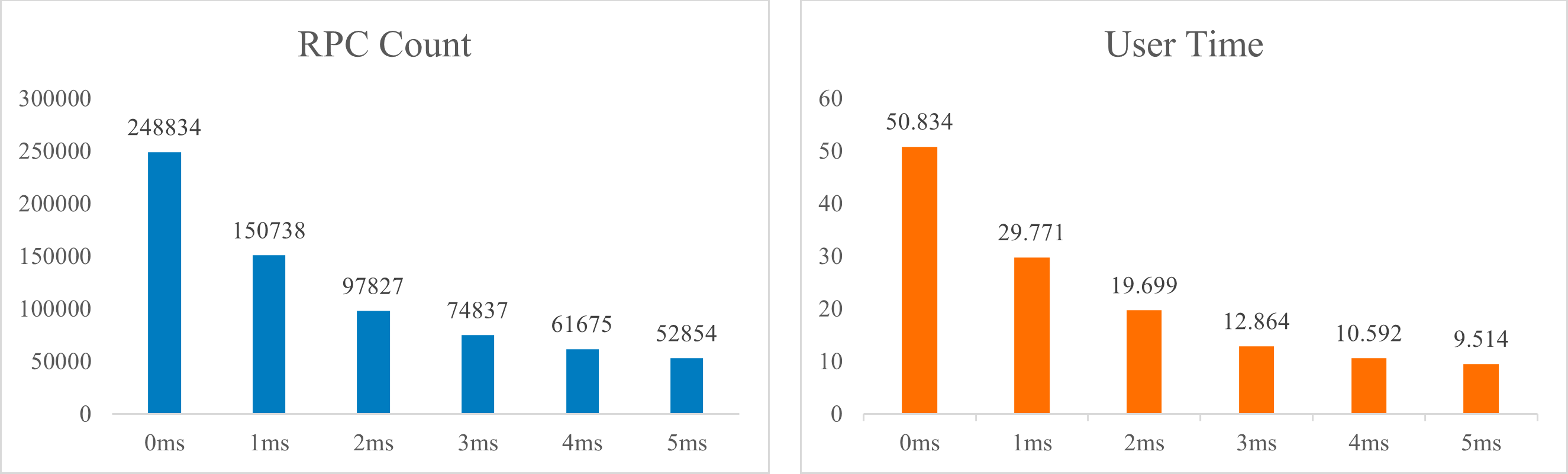
从图中可以看到,RPC数量和CPU时间随着延迟毫秒数的增加而显著减少,证明了增加延迟可以极大地减轻服务器的压力。
下面我们再来看看提交的日志总数:
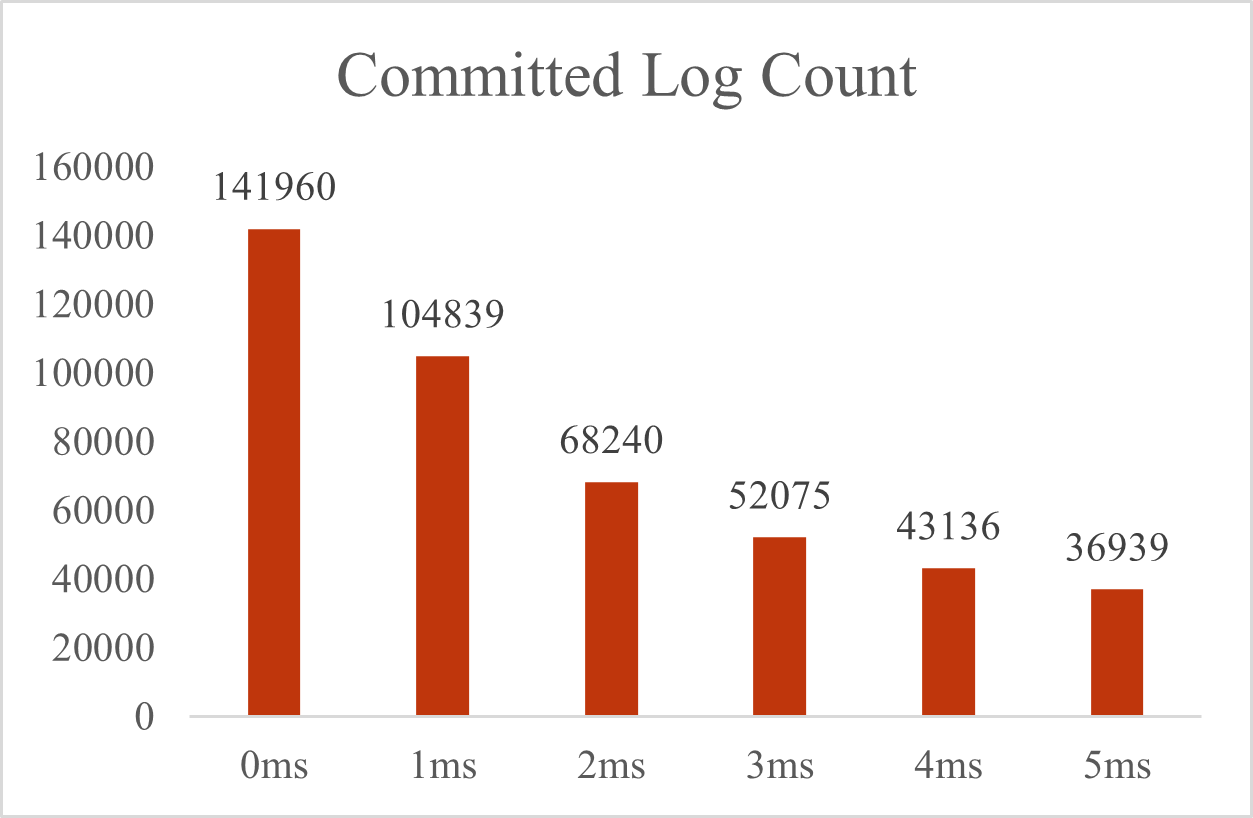
可以看到,在没有延迟的时候,最高的QPS已经达到了8800。
看到这样的趋势变化,你可能会问:不是降低了服务器压力吗,为什么提交日志总数不增反降呢?
原因就在于,客户端需要等到服务端的响应才能继续发送下一个请求,除了客户端与服务端交互、Raft节点间交换的延迟外,服务端还增加了批量发送延迟,相应地客户端获取到服务端的响应也会延迟,从而延迟了下一条请求的发送,因此向服务端发送的请求数也减少了。这种方法其实可以看成用延迟来换吞吐量。所以看似性能降低,其实瓶颈在于客户端的发送的请求数,如果多增加一些客户端,就可以看到这种优化的方法可以极大的增加服务器的吞吐量。但是限于我本机的硬件配置,继续增加模拟的客户端会消耗本地的CPU资源,客户端发送和服务端响应的速度都会变慢,因此无法在客户端数量上进行对比实验,如果有多台机器模拟客户端向服务端发送请求,我认为吞吐量一定是远远大于8800QPS的。
解决内存泄露问题
对Raft进行测试时,我发现有时会出现数据竞争的情况,并且Go提示出现在切片中。我检查到在进行切片的读写过程中都进行了加锁,并且使用的是不同的变量,但是依然出现了数据竞争,令我百思不得其解。数据竞争发生在Leader向Follower发送RPC请求时获取参数时:
1 | entries = rf.log[rf.getLogIndex(nextIndex):] |
以及Leader变为Follower接收新Leader的RPC,并且发生冲突截取日志时:
1 | rf.log = rf.log[:startLogIndex] |
我后来了解到,为了提高效率,Go切片底层的内存其实是复用的,并不会对其进行复制,这就解释了为什么会发生数据竞争的问题:entries和rf.log底层是同一个数组,共享同一片内存区域。
除了会出现数据竞争,还可能会造成内存泄露:如果在一个切片的基础上进行切片,其他部分的内存很可能得不到释放。例如:
1 | s1 := make([]int, 0) |
在上述代码中,实际上第5行代码执行完切片后,并没有将s1复制一份给s2,而是复用了s1底层数组。如果数组中有元素一直被变量引用的话,整个底层数组的内存就会得不到释放,造成内存泄露。详情可参考这篇博文。
为了避免内存泄露,可以使用内置的copy()函数:
1 | b := make([]T, len(a)) |
或者创建新的切片,并使用append()附加到新切片后面:
1 | b = append([]T(nil), a...) |
更多关于Go切片的使用可以参考Go的官方wiki:SliceTricks。
因此Raft中的数据数据竞争与内存泄露问题得以解决:
1 | entries = append([]LogEntry(nil), rf.log[rf.getLogIndex(nextIndex):]...) |
而rf.log = rf.log[:startLogIndex]这一部分可以不用修改,因为后续还会继续接收新的日志,复用内存可以提高效率。
锁的优化
Raft的实现不可避免的会在很多地方使用锁,因此很多同学希望通过对锁的进行优化来提高性能,事实真的如此吗?
使用细粒度的锁
我一开始也希望可以通过减小锁的粒度来提高并发性能,但是在实现到一半我便放弃了,重新改用了一把大锁。总的来说有以下几点原因:
- 很多地方都要使用到Raft的全局共享变量,例如
commitIndex、currentTerm等,如果不小心处理容易导致死锁。 - 如果使用到全局共享变量时上全局锁,使用到粒度更小的变量时,释放全局锁,然后使用细粒度锁,这样代码实现起来非常不优雅。
- 如果加锁解锁非常频繁,势必会带来额外的性能开销,这样不如只使用一把大锁。
综合以上考量,我并没有使用更细粒度的锁来对Raft进行优化。
使用读写锁
通过读写锁来优化并发性能也是一个好的想法,但是要特别注意,加锁时读到的数据,如果在后面用到的时候数据已经被再次修改,是否会造成影响,如果会受到影响,则应该全程加锁。例如:
1 | if rf.checkStateIsNewWithLock(currentTerm, LEADER) { |
在rf.checkStateIsNewWithLock()函数中,我在判断节点状态是否发生改变时使用了读锁,在判断完成后使用写锁。
乍一看你可能觉得这样做没有任何问题,实际上问题很大。设想一下这样一种情况,在第1行判断完节点状态后,这时由于节点接收到来自新节点的AppendEntries RPC,从Leader变成了Follower,第2行在等待获取锁。如果第2行获取到了锁,然后直接执行操作,这样就会造成系统混乱。
正确的使用方法是,直接在第1行前面加写锁,然后使用不加锁的rf.checkStateIsNew()函数进行判断:
1 | rf.mu.Lock() |
事实上,实现Raft时,我并没有在很多场景下使用到读锁(如上图),因为很多时候读完数据就需要立马对共享数据进行操作,使用到读锁的情况大部分情况都是判断完状态后进行等待的:
1 | for rf.checkStateIsNewWithLock(currentTerm, LEADER) { |
以上便是我对Raft进行优化的全过程。
MIT 6.5840 分布式系统(Spring 2023)丨Lab 2:Raft的极致优化,Part 2D测试时间缩短到115s!
http://jjzhong.com/2023/08/20/MIT 6.5840 分布式系统(Spring 2023)丨Lab 2:Raft的极致优化,Part 2D测试时间缩短到115s!/